记一次TensorFlow tf.summary.image对生成batch数据的影响
最近在尝试用TensorFlow标准文件格式tfrecords和内置的文件队列向模型读入数据。 首先分别创建train和test两个文件队列,读入mnist数据,生成train和test的两个batch的tensor: img_batch,label_batch和test_img_batch, test_label_batch。然后用tf.summary.image()在tensorboard的IMAGES栏里显示图片。最后在sess里用两个sess分别生成以batch的训练数据和测试数据。代码如下:
train_queue = tf.train.string_input_producer([train_tfrecords])
test_queue = tf.train.string_input_producer([test_tfrecords])
img, label = mnist.read_and_decode(train_queue)
test_img, test_label = mnist.read_and_decode(test_queue)
img_batch, label_batch = tf.train.batch([img, label], batch_size=2, capacity=20)
test_img_batch, test_label_batch = tf.train.batch([test_img, test_label], batch_size=2, capacity=20)
img_writer = tf.summary.FileWriter(os.path.join('logs', dataset), graph=tf.get_default_graph())
tf.summary.image('images', img_batch)
tf.summary.image('test_images', test_img_batch)
with tf.Session(config=tf_config) as sess:
merged = tf.summary.merge_all()
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
for i in xrange(10):
if coord.should_stop():
break
imgs, labels, summary = sess.run([img_batch, label_batch, merged])
print("step {}: train labels {}".format(i, labels))
test_imgs, test_labels = sess.run([test_img_batch, test_label_batch])
print("step {}: test labels {}\n".format(i, test_labels))
img_writer.add_summary(summary, i)
except Exception, e:
coord.request_stop(e)
finally:
coord.request_stop()
coord.join(threads)
img_writer.close()
一个sess里运行训练数据的batch和summary:
imgs, labels, summary = sess.run([img_batch, label_batch, merged])
另一个sess里运行测试数据的batch:
test_imgs, test_labels = sess.run([test_img_batch, test_label_batch])
而问题就出在这个两个分开的sess和收集了summary的merged变量。在第一个sess里运行训练数据的batch和merged时,尽管只是生成训练数据,没有显式生成测试数据,但是由于merged里收集了train和test的图像数据,这个sess也会生成测试数据。在tensorboard里训练和测试的数字输出如下: 测试文件图像数字是: [7, 2, 1, 0, 4, 1, 4, 9, 5, 9, 0, 6, 9, 0, 1, 5, 9, 7, 3, 4, 9, 6, 6, 5, 4, 0, 7, 4, 0, 1, 3, 1, 3, 4, 7, 2, 7, 1, 2, 1, 1, 7, 4, 2, 3, 5, 1, 2, 4, 4, 6, 3, 5, 5, 6, 0, 4, 1, 9, 5, 7, 8, 9, 3, 7, 4, 6, 4, 3, 0, 7, 0, 2, 9, 1, 7, 3, 2, 9, 7, 7, 6, 2, 7, 8, 4, 7, 3, 6, 1, 3, 6, 9, 3, 1, 4, 1, 7, 6, 9] 生成的test_images batch: step 1: (7, 2) step 2: (4, 1) step 3: (5, 9) step 4: (9, 0) … 会间隔一个batch生成数据
而在生成测试的batch数据的Session里,会相应生成 step 1: (1, 0) step 2: (4, 9) step 3: (0, 6) step 4: (1, 5)
… 这相当于第一个sess里运行merged会生成测试的batch数据,至于为什么和第二个sess生成测试数据间隔生成数据,这是因为文件队列会通过Reader将文件里的数据读入到example queue中,每生成一个batch的数据会从example queue拿出数据,而先后执行sess.run([merged])和sess.run([test_img_batch, test_label_batch])都会从example queue里输出测试数据,而导致间隔生成测试数据的现象。TensorFlow通过队列读入文件的示意图如下:
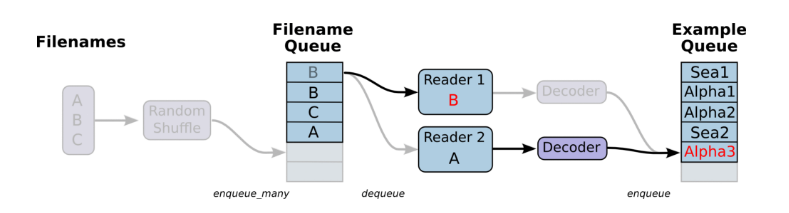
正确方式是将生成train和test的数据放在同一个Session里,代码如下:
with tf.Session(config=tf_config) as sess:
merged = tf.summary.merge_all()
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
for i in xrange(10):
if coord.should_stop():
break
imgs, labels, test_imgs, test_labels, summary = sess.run([img_batch, label_batch, test_img_batch, test_label_batch, merged])
print("step {}: train labels {}".format(i, labels))
print("step {}: test labels {}\n".format(i, test_labels))
img_writer.add_summary(summary, i)
except Exception, e:
coord.request_stop(e)
finally:
coord.request_stop()
coord.join(threads)
img_writer.close()