AROMA: Activity Recognition using Deep Multi-task Learning
In activity recognition, simple and complex activity recognition are a pair of related tasks. Simple acitvities are usually characterized by repeated and low-level actions, e.g., runing, sitting, and walking. Compared to simple activities, complex activities are more complicated and high-level activities like working, having dinner, commuting. And a complex activity may include several low-level simple activities. For instance, having dinner, a kind of complex activity, can include standing and walking to select food and sitting at the table to eat, the simple activities. In other words, simple activities can be regarded as the components of complex activity. In our model called AROMA, we use multi-task learning to recognize simple and complex activities simultaneously by using a shared representation to improve generalization and accuracy of the model (Our paper “AROMA: A deep multi-task learning based simple and complex activity recognition method using wearable sensors” has been submitted to 2017 AAAI). Here is the code.
Methodology
Our model AROMA recognizes simple and complex activities simultaneously. It divides raw sensor data to fixed length time windows. Since complex activities usually last for a longer duration than simple activities, each complex activity sample contains multiple simple activity samples. For each simple activity sample, AROMA utilizes a CNN to extract deep features, which are inputted into a simple activity classifier directly. For each complex activity sample, apart from CNN, AROMA also applies a LSTM network to learn the temporal context of activity data. Simple and complex activity recognition are two tasks in this work. The two tasks have the same input and share representations (the red squares): 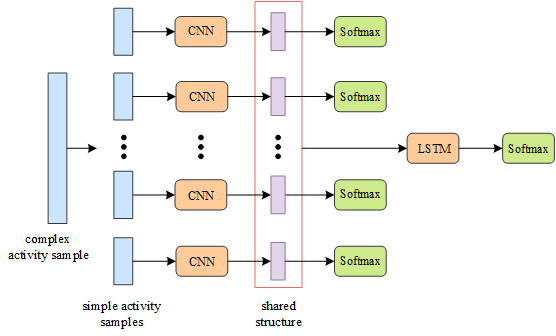
Definition
- A window is a three-tuple $win = (X, t_s, t_e)$, where $X$ denotes the sensor data, $t_s$ and $t_e$ are the starting and ending time of the window respectively.
- $l_s$ is the window length of simple activity, $l_c$ is the window length of complex activity. And a window of complex activity contains $l_c/l_s$ windows of simple activity.
- A simple activity sample is the pair $(win_{ls}, y_s)$. A complex activity sample is the pair $(win_{l_c}, y_c)$. Since each complex activity contains multiple simple activity samples, it means a complex activity smaple pair $(win_{l_c}, y_c)$ contains $l_c/l_s$ simple activity sample pairs $(win_{ls}^i, y_s^i)$
Simple Activity Recognition Task
Our model uses deep convolutional neural networks (CNN) to learn deep features. Since deeper networks are not able to achieve expected performance, we apply the ResNet proposed by He et al(2016) to our model. The architecture of simple acitivity recognition task: 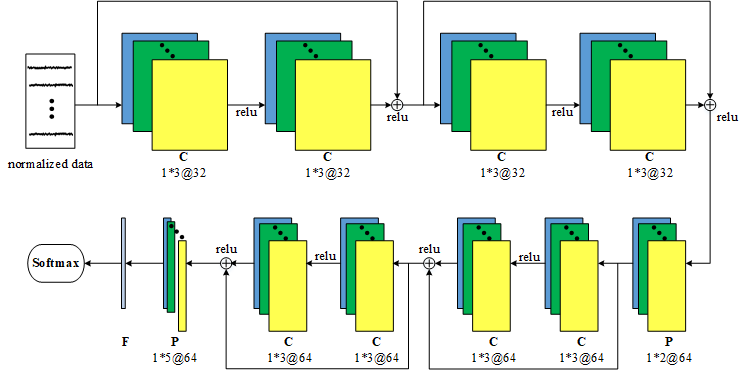
Complex Activity Recognition Task
Our model applies a LSTM network to implement complex activity recognition task. Figure 3 shows the workflow of complex activity recognition task. We adopt a three-layer LSTM network. As we know, within a single complex activity sample, there are lc/ls simple activity samples. The output of the previous LSTM unit is inputted to the next unit. In this way, the temporal context of complex activities can be learnt. The input of the first layer is the simple activity feature representations after fully connected. It is also a shared representation between simple and complex activity recognition tasks. The output of the LSTM network is served as the input of a softmax classifier, which predicts complex activity labels.
Multi-task learning
We train the $lc/ls$ simple activity tasks in one complex activity window and the complex activity task jointly and simultaneously. The loss functions of simple activity tasks are:
$L_s^i = -\frac{1}{m}logf_s^i$
the loss functions of complex activity tasks are:
$L_c = -\frac{1}{m}logf_c$
where $i = 1, 2, \ldots,lc/ls$, $m$ is the mini-batches, $f$ is classifer function.
The goal of our model is to train two satisfactory classifi- ers by minimizing these two loss functions as follows:
$argmin\frac{1}{lc/ls}\sum_{i=1}^{lc/ls}L_s^i + L_c$
Experiments
Dataset
We use a public activity recognition dataset in our experiment: Huynh dataset (Huynh, Fritz, and Schiele 2008). Huynh dataset consists of two level activity labels: activities and daily routines, where activities are the components of daily routines. Thus, they respectively correspondinsimple activities and complex activities in this work.
| type | |
|---|---|
| Simple Activities | sitting/ desk activities, lying while reading/ using computer, having dinner, walking freely,driving car, having lunch, discussing at whiteboard, attending a presentation, driving bike, watching a movie, standing/ talking on phone, walking while carrying something, walking, picking up cafeteria food, sitting/ having a coffee, queuing in line, personal hygiene, using the toilet, fanning barbecue, washing dishes, kneeling/ doing something else, sitting/ talking on phone, kneeling/ making fire for barbecue, setting the table, standing/ having a coffee, preparing food, having breakfast, brushing teeth, standing/ using the toilet, standing/ talking, washing hands, making coffee, running,and wiping the whiteboard |
| Complex Activities | dinner activities, commuting, lunch routine, office work |
We preprocess the dataset by removing the unlabeled data and prune it into the proper window size, which can be downloaded at huynh.cp. The dataset path has to be appointed in config.py:
self.dataset = "huynh/dataset/path"
Comparison
To evaluate the effectiveness of our model, we compare it with the following baseline methods. For fair comparison, all baseline methods set the sample lengths of simple and complex activities as the same as AROMA.
- STL. STL is the short form of single task learning. STL recognizes simple and complex activities separately. Forthe two tasks, STL utilizes the same network and parameters with AROMA. Differently, there is no shared structure between these two tasks, and the loss functions of two tasks are minimized separately.
- DCNN. DCNN (Yang et al. 2015) is also a single task learning method that recognizes simple and complex activities using a deep convolutional neural network.
- DeepConvLSTM. DeepConvLSTM (Ordónez and Roggen 2016) recognizes activities based on convolution operations and LSTM units.
- TM. TM stands for topic model. Referring to Huynh,Fritz, and Schiele (2008), TM treats a complex activity sample as a “document”, which is composed of a corpus of “words” (i.e., simple activity samples). The recognition accuracies of these models and ours:
The structure of the project
- TensorFlow version: 1.2.1
- config.py: containing parameters the model will use, like window length of simple activity and complex activity, training parameters e.g., batch size, learning rate decay speed.
- utils.py: containing commonly used functions in the project
- joint_model.py: building and training the model
- main.py: entrance of the project You can run main.py -h to get the args:
python main.py -h
Three args would be listed:
optional arguments:
-h, --help show this help message and exit
--test TEST select the test day. Max num is 6
--version VERSION model version
--gpu GPU assign task to selected gpu
For Leave-one-out cross-validation, the “test” option should be assigned to test one day data in the dataset. Therefore, for example, you can run:
python main.py --test 0 --version har-model --gpu 0